Optical Character Recognition (OCR)
Optical Character Recognition ist ein Verfahren zur automatischen Schrifterkennung und zielt darauf ab, Zeichen (Buchstaben, Zahlen) aus Bilddateien zu erkennen diesen Zeichen dann Zahlenwerte zuzuordnen (ASCII, Unicode), welche der Computer dann als elektronischen, durchsuchbaren Volltext auslesen kann. Durch moderne Algorithmen können neben Druckbuchstaben auch handgeschriebene Texte erkannt werden. Heute wird zudem Intelligent Character Recognition (ICR) hinzugenommen, um kontextbasiert die erkannten Zeichen zu korrigieren. Eine erkannte „1“ kann somit in ein „I“ korrigiert werden, wenn es innerhalb eines Wortes verwendet wird. Erkannt: „Ha1lo“ -> Korrigiert: „Hallo“
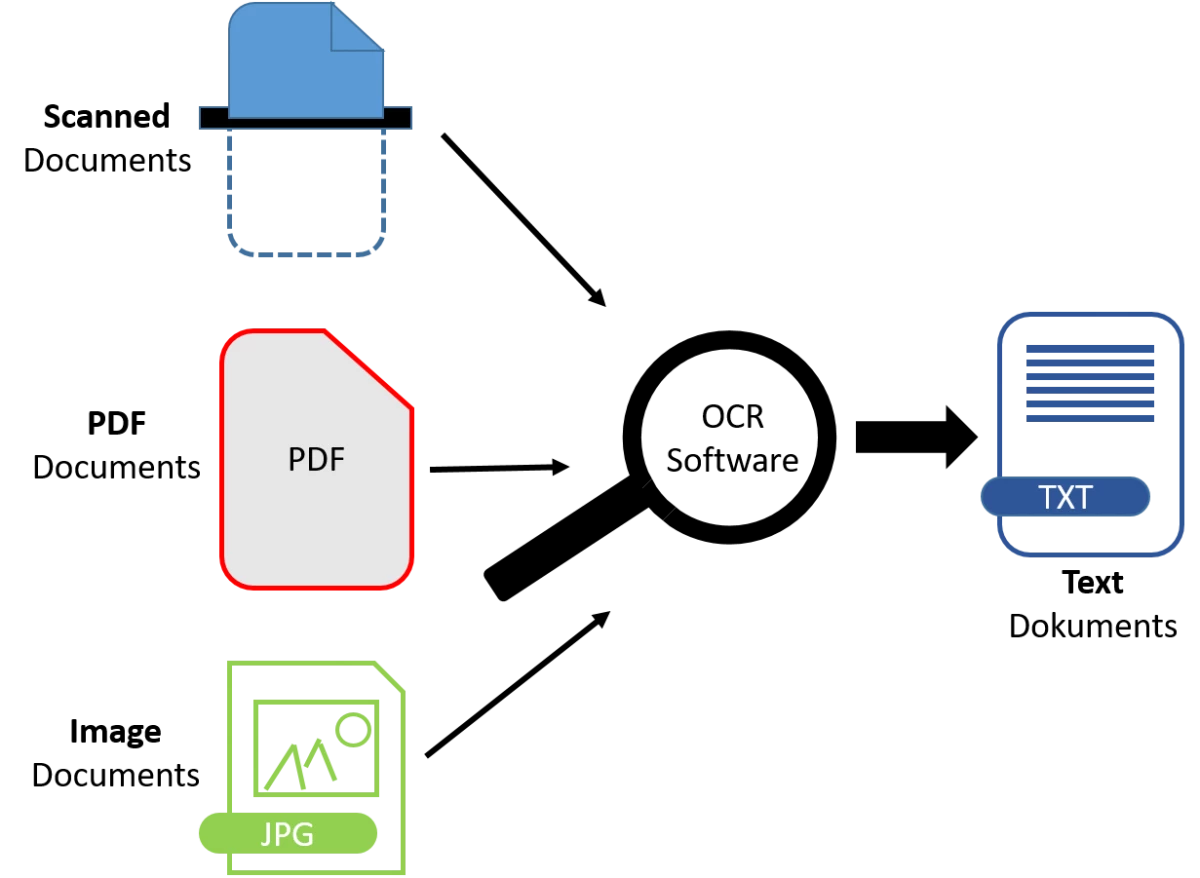 OCR-Möglichkeiten
OCR-Möglichkeiten© Eigene Darstellung (Credits: Lukas Rengbers)
Anwendungsbeispiele
Arztrezepte auslesen
Auslesen von handgeschriebenen Arztrezepten
Post-Sortierung
Handschriftlich beschriebene Briefe werden durch Kameratechnik erfasst. Dabei werden die Zeichen durch OCR erkannt und die Briefe entsprechend sortiert.
Adobe Acrobat OCR
Gescannte Dokumente können einfach und schnell in PDF-Dateien mit bearbeitbarem Text umgewandelt werden.
Automatisierte Digitalisierung historischer Drucke
Mittlerweile können auch historische Drucke mit uneinheitlicher Orthografie, häufigen Eigennamen und variierendem Schriftbild zufriedenstellend erkannt werden.